OMSCS-ML课程笔记03-Neural Networks
这个系列是Gatech OMSCS 机器学习课程(CS 7641: Machine Learning)的同步课程笔记。课程内容涉及监督学习、无监督学习和强化学习三个部分,本节主要介绍监督学习中神经网络的相关内容。
神经网络(neural networks)是一种十分强大的机器学习模型,在分类和回归问题中都有非常多的应用。某种意义上将我们可以把神经网络看做是对生物神经系统的抽象:每个神经元只负责简单的处理和信号收发,将不同的神经元连接起来形成一个网络就可以解决复杂的问题。
神经元作为神经网络中最基本的结构负责对来自其他神经元的信号按权重进行相加,当累积的信号超过阈值时神经元被激活并向它后面的神经元发射一个信号。上述过程可以表示为:
\[y = f(\sum_{i=1}^n \omega_i x_i + b)\]
Perceptron
最简单的神经网络为感知机(perceptron),此时神经元的阈值为0且对应激活函数为单位阶跃函数(heaviside step function):
\[f(x) = \left\{ \begin{aligned} & 1, & & x \geq 0 \\ & 0, & & \text{otherwise} \end{aligned} \right.\]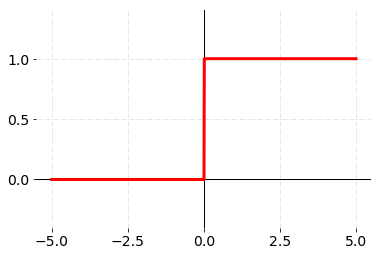
感知机可以用来解决二分类问题,而且通过调整神经元的权重单层感知机可以表示所有的基本逻辑运算符包括AND、OR、NOT等。实际上此时感知机的决策边界为二维平面上的直线,只要数据线性可分(linearly separable)就一定可以用感知机来描述。相应地,如果数据不是线性可分则不能使用感知机进行描述。一个经典的例子是异或运算XOR:单层感知机无法表示异或运算,需要使用多层感知机才能处理线性不可分的问题。

Sigmoid
感知机使用单位阶跃函数作为激活函数,它的主要缺陷在于函数在0点不可导而在其他位置导数恒为0。在神经网络中更常用的函数是sigmoid函数,其定义为:
\[\sigma(x) = \frac{1}{1 + e^{-x}}\]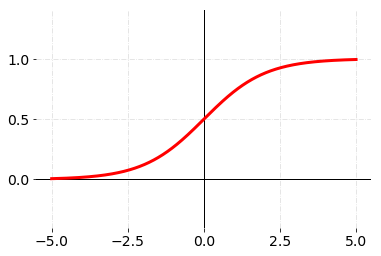
显然sigmoid函数更加光滑,而且由于函数自身的归一化性质我们也可以把函数的输出视为概率进而应用到分类问题中。神经网络中其他常用的激活函数可参见Activation Functions。
Neural Network Sketch
我们把神经元按照一定的拓扑关系连接起来就形成了神经网络。一般而言网络可分为输入层、隐层和输出层,其中隐层和输出层对应网络的主要计算过程。同时由于网络的每一层都是可导的,我们可以从后向前计算输出对输入的导数,这就为神经网络的训练提供了理论保证。
Training
Perceptron Training
感知机的学习算法如下:
- 初始化神经元权重\(\omega\)以及学习率\(\eta\);
- 对数据集进行遍历:
- 计算感知机在当前数据上的预测值\(\hat{y} = (\omega^T x \geq 0)\);
- 如果感知机对当前数据预测正确则继续遍历;
- 否则更新参数\(\omega \leftarrow \omega + \eta (y - \hat{y}) x\)。
感知机的学习算法可以理解为根据数据预测值与实际的误差来调整神经元权重,调整的幅度由学习率\(\eta\)进行控制。同时可以证明对于线性可分的数据,采用上述的感知机学习算法在有限次迭代后一定可以将数据完美划分。
Gradient Descent
我们将感知机学习的思想推广到更一般的情况中,就能得到神经网络训练常用的梯度下降算法(Gradient Descent):
- 初始化神经元权重\(\omega\)以及学习率\(\eta\);
- 对数据集进行遍历:
- 计算神经网络在当前数据上的误差\(E\);
- 计算误差关于每个权重\(\omega_i\)的偏导数\(\frac{\partial E}{\partial \omega_i}\);
- 更新每个参数\(\omega_i \leftarrow \omega_i - \eta \frac{\partial E}{\partial \omega_i}\);
- 重复以上步骤直至数据集上总误差收敛。
因此对于不同类型的任务只需要选择合适的误差函数并计算相应的偏导数即可。对于大型神经网络显式计算偏导数基本是不现实的,实际中一般是通过反向传播算法(backpropagation)从后向前计算每一层的偏导数。同时需要说明的是与感知机学习算法不同,梯度下降算法不能保证收敛到全局最优。
Bias
Restriction Bias
最后我们来讨论神经网络的偏好。从前面的内容中不难发现神经网络的限制是比较少的,即使是感知机也有非常强的表达能力。实际上通用逼近定理(universal approximation theorem)证明了对于任意的连续函数,只要有足够多的神经元我们可以通过单隐层神经网络以任意精度进行近似。这表明神经网络具有非常强大的表达能力,当出现其他模型无法处理的情况时神经网络仍然可以有非常好的表现。同时需要注意的是神经网络强大的表达能力也说明它非常容易出现过拟合的问题,因此在使用时往往还需要结合正则化、交叉验证等方法来对模型的复杂度进行控制。
Preference Bias
神经网络的偏好还取决于网络的初值。由于梯度下降会使模型向最小化误差的方向移动,初值的选取对于模型的最终性能起着至关重要的作用。通常情况下我们会选择比较小的随机值来初始化网络,这意味着模型的复杂度会相对较低而且每次训练模型不会卡在某些局部极小值上。因此神经网络在训练时同等条件下会优先选择相对简单的模型。
Reference
- Chapter 4: ARTIFICIAL NEURAL NETWORKS, Machine Learning, Tom Mitchell, McGraw Hill, 1997.
- Wikipedia: Universal approximation theorem