深蓝学院-GNN课程笔记02-深度学习基础
这个系列是深蓝学院图深度学习理论与实践的同步课程笔记。课程内容涉及图深度学习的基础理论与应用,本节主要介绍深度学习的基础知识。
深度学习简史
所谓深度学习(Deep Learning)是指使用深层的神经网络来解决机器学习的问题,其大致发展脉络如下:


早在上世纪四十年代研究人员就受到生物神经系统的启发提出了人工神经元模型(McCulloch-Pitts neuron)。在五十年代,人工神经网络不断发展并产生了感知机模型(perceptron)。到了六十年代,反向传播(backpropagation)的思想最早出现在控制理论中,随后由Hinton等拓展到神经网络的训练过程并一直沿用到今天。而在八十年代出现了早期的卷积神经网络(convolutional neural network, CNN)和循环神经网络(recurrent neural network, RNN)等模型,并在图像识别以及时间序列分析等领域都得到了一定的应用。

进入二十一世纪,随着数据量以及计算能力的增长,深度学习取得了爆发性的进步。高速GPU的出现使得训练大规模神经网络模型成为了可能,同时超大规模训练数据库的出现又保证了模型具有足够强的泛化能力。因此深度学习的相关方法在各种各样应用中的表现都远远高于传统的机器学习方法,在不同的研究领域中都取得了巨大的成功和社会影响力。在2012年的ILSVRC图像识别竞赛中,使用深度卷积网络的AlexNet将图像识别的错误率由25.8%降低到了16.4%。随后几年深度卷积网络迅速统治了图像识别领域并成功将图像识别的错误率降低到了3.5%,已经低于人眼的识别错误率。2016年基于深度强化学习(deep reinforcement learning)的AlphaGo模型首次在围棋领域击败了人类最强棋手,这一成绩使得人工智能的概念进入到大众视野。到了2018年,基于深度学习的预训练语言模型BERT横空出世并在自然语言处理(natural language processing, NLP)的各个领域中都取得了突破性的进步。同年,图灵奖颁发给了Yoshua Bengio,Geoffrey Hinton以及Lann Lecun以表彰他们在深度学习领域做出的奠基性工作。

前馈神经网络
网络结构
最简单的深度学习模型是前馈神经网络(feedforward neural network),网络包括一个输入层、若干个隐层以及一个输出层,从而将一个输入向量映射为输出向量。

在隐层中每个神经元接收来自前一层的输入信号并进行加权求和,然后通过一个非线性激活函数(activation function)将累计的信号进行激活从而得到传递给下一神经元的输出值。单个神经元的计算过程如下图所示。

将每一个隐层的神经元放到一起可以得到矩阵形式的前向计算公式:
\[h^{(k+1)} = f^{(k+1)} (h^{(k)}) = \alpha(b^{(k)} + W^{(k)} h^{(k)})\]其中\(h^{(k)}\)为第\(k\)个隐层的输出向量;\(W^{(k)}\)为第\(k\)个隐层的权重矩阵;\(b^{(k)}\)为第\(k\)个隐层的偏置向量。
激活函数
每个神经元通过非线性激活函数来增强它的表达能力,常见的激活函数包括ReLU、sigmoid以及tanh等。
\[\text{ReLU} (x) = \max \{ x, 0\}\]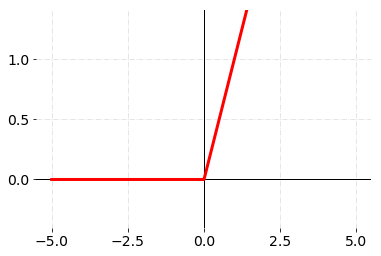
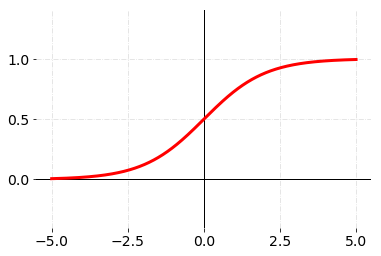
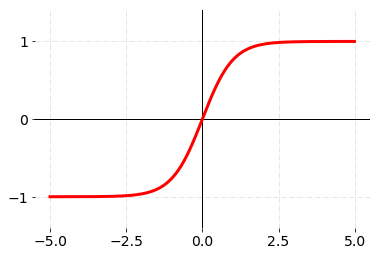
值得一提的是sigmoid函数和tanh函数都存在一定的饱和问题。当输入\(x\)过大或者过小时,函数的梯度都趋于0;只有当输入\(x\)在0附近时两个激活函数才会比较敏感。因此现代神经网络中使用sigmoid和tanh函数的模型越来越少,大多数模型都会默认选择ReLU作为激活函数。
输出层和损失函数
神经网络的输出层和一般的隐层并没有本质的区别,仍然是对前一层进行加权求和。但需要主要的是大多数情况下输出层不包含激活函数。
\[\hat{y} = W h + b\]
除了模型之外我们还需要损失函数(loss function)来度量网络的输出与ground truth的差异。对于回归问题一般可采用平方误差作为损失函数:
\[L(y, \hat{y}) = (y - \hat{y})^2\]而对于分类问题则需要使用softmax函数将网络输出转换成类别向量,然后利用交叉熵(cross entropy)计算损失:
\[z = W h + b\] \[\hat{y}_i = \frac{\exp (z_i)}{\sum_j \exp (z_j)}\] \[L(y, \hat{y}) = -\sum_i y_i \log ( \hat{y}_i )\]神经网络的训练
梯度下降
我们通过在训练数据集上最小化损失函数来实现神经网络的训练。显然神经网络的训练过程是一个优化问题,可以通过梯度下降(gradient descent)的方法进行求解:
\[W_{n+1} \leftarrow W_{n} - \eta \frac{\partial L}{\partial W_n}\]
其中\(W_n\)为网络在当前步的参数;\(\eta\)为学习率(learning rate),它控制了每次进行梯度下降的步长。
由于在整个数据集上计算导数十分消耗计算资源,在大多数情况下我们会每次在数据集上采样出一小部分数据来进行计算,此时梯度下降算法称为小批量梯度下降(mini-batch gradient descent)。除此之外,梯度下降还存在一些变体如Adagrad、Adadelta以及Adam算法等。这些变体使用了动量项(momentum)来修正梯度值,因此在很多情况下会有更好的收敛性。
反向传播
通过梯度下降训练神经网络首先需要知道损失函数对于模型参数的梯度,一般是通过反向传播算法来进行计算。反向传播算法的本质是利用链式法则(chain rule)从后向前逐层计算导数。对于可导的损失函数\(L\)首先计算它对于输出层的导数\(\frac{\partial L}{\partial o}\),根据链式法则\(l\)对于最后一个隐层的导数为:
\[\frac{\partial L}{\partial h^k} = \frac{\partial o}{\partial h^k} \cdot \frac{\partial L}{\partial o}\] \[\frac{\partial L}{\partial w_{h^k}} = \frac{\partial o}{\partial w_{h^k}} \cdot \frac{\partial L}{\partial o}\]类似地,损失函数\(l\)对于第\(r-1\)层的导数为:
\[\frac{\partial L}{\partial h^{r-1}} = \frac{\partial h^r}{\partial h^{r-1}} \cdot \frac{\partial L}{\partial h^r} = \frac{\partial h^r}{\partial h^{r-1}} \cdot \bigg( \frac{\partial h^{r+1}}{\partial h^r} \cdots \frac{\partial o}{\partial h^k} \cdot \frac{\partial L}{\partial o} \bigg)\] \[\frac{\partial L}{\partial w_{h^{r-1}}} = \frac{\partial h^{r-1}}{\partial w_{h^{r-1}}} \cdot \frac{\partial L}{\partial h^{r-1}} = \frac{\partial h^{r-1}}{\partial w_{h^{r-1}}} \cdot \bigg( \frac{\partial h^r}{\partial h^{r-1}} \cdots \frac{\partial o}{\partial h^k} \cdot \frac{\partial L}{\partial o} \bigg)\]
其中\(\frac{\partial L}{\partial h^{r-1}} = \frac{\partial h^r}{\partial h^{r-1}} \cdot \big( \frac{\partial h^{r+1}}{\partial h^r} \cdots \frac{\partial o}{\partial h^k} \cdot \frac{\partial L}{\partial o} \big)\)可通过从后向前递推,因此每次只需要单独计算每一层的导数\(\frac{\partial h^{r-1}}{\partial w_{h^{r-1}}}\)即可。
预防过拟合
深度神经网络往往具有大量的模型参数因此容易出现各种过拟合问题。常用的预防过拟合技术包括加入正则化项(regularization)、随机失活(dropout)以及批量归一化(batch normalization)等。正则化项是指对模型的参数加以约束,防止模型参数出现过于大的值,一般可通过在损失函数中加入模型参数的L1或L2范数来实现。随机失活是指在模型训练过程中随机将一部分神经元的输出置为0,仅保留剩余神经元的计算结果并送入下一层中。通过随机失活可以约束模型的表达能力从而防止出现过拟合的现象。而批量归一化则是对隐层的输出向量进行标准化,将隐层的输出规范化到一定的范围上从而对模型的学习能力进行限制。
卷积神经网络
卷积神经网络是一种常用的深度学习模型,它将图像卷积运算融合到深度神经网络中。在卷积神经网络出现之前,对于图像识别问题一般是将二维图像展开成一个向量然后按标准的分类问题进行处理。然而这种处理方式存在一些问题:显然图像中的物体存在一定的局部结构,将图像直接展开程向量破坏了局部的结构使得图像识别更加困难。

将卷积运算结合到神经网络中会带来很多好处:首先和传统的隐层运算相比卷积运算是稀疏的。卷积运算的稀疏性使得卷积神经网络的时间复杂度和空间复杂度都远小于同等输入的前馈神经网络。

卷积神经网络的另一个优势在于模型的参数是共享的,在每次运算时都是使用同一套参数。因此卷积神经网络的参数量远低于前馈神经网络,在训练时对内存的需求要小得多也不容易出现过拟合的问题。

此外,卷积运算还具有平移不变性:当输入信号发生平移时对应的输出信号也会发生平移。因此无论图像中的物体出现在什么位置,卷积神经网络总能捕捉到物体的信息。


除了卷积运算外,在卷积神经网络中通常还会包含池化(pooling)运算来对图像进行降采样。常用的池化运算包括最大值池化(max pooling)和均值池化(average pooling)。

通过卷积运算和池化操作可以提取到图像中的信息称为特征图(feature map),将特征图展开后就可以送入下游的前馈神经网络中进行图像分类等任务。

循环神经网络
另一种常用的深度学习模型是循环神经网络,通常用来处理语音识别、机器翻译以及文本情感分析等时间序列问题。这类问题的特点是模型的输入和输出均为不定长的序列,同时输入的关键信息可能会出现在序列中的任意位置,因此很难使用标准的前馈神经网络来进行处理。
循环神经网络中使用了一个独立的隐层来处理时间序列中的每一个元素。该隐层接收时间序列中的一个元素以及上一个隐状态(hidden state),然后更新隐状态并返回输出元素:
\[h^{(i)} = \alpha_h (W_{hh} h^{(i-1)} + W_{hx} x^{(i-1)} + b_h )\] \[y^{(i)} = \alpha_y (W_{yh} h^{(i)} + b_y )\]
而在反向传播时则需要从后向前将每一步的梯度进行累加(乘):

标准循环神经网络的一个缺陷在于难以捕捉长距离元素之间的关系。这是由于在反向传播过程中前面元素的梯度需要从后向前进行累乘,因此容易出现梯度消失或是爆炸的问题。为了提高RNN处理长序列的能力,在长短期记忆网络(long short-term memory, LSTM)中额外引入了单元状态(cell state)作为长期记忆。LSTM的前向传播过程如下:
\[f_t = \sigma(W_f x^{(t)} + U_f h^{(t-1)} + b_f)\] \[i_t = \sigma(W_i x^{(t)} + U_i h^{(t-1)} + b_i)\] \[o_t = \sigma(W_o x^{(t)} + U_o h^{(t-1)} + b_o)\] \[\tilde{C}^{(t)} = \tanh (W_c x^{(t)} + U_c h^{(t-1)} + b_c)\] \[C^{(t)} = f_t \odot C^{(t-1)} + i_t \odot C^{(t-1)}\] \[h^{(t-1)} = o_t \odot \tanh (C^{(t-1)})\]
与LSTM类似的还有门控循环单元(gated recurrent unit, GRU),它将遗忘门和输入门合并为更新门并且将单元状态合并到隐状态中,对应的前向传播过程如下:
\[z_t = \sigma(W_z x^{(t)} + U_z h^{(t-1)} + b_z)\] \[r_t = \sigma(W_r x^{(t)} + U_r h^{(t-1)} + b_r)\] \[\tilde{h}^{(t)} = \tanh (W x^{(t)} + U \ (r_t \odot h^{(t-1)}) + b)\] \[h^{(t)} = (1 - z_t) \odot h^{(t-1)} + z_t \odot \tilde{h}^{(t)}\]
自编码器
深度学习的另一个重要应用是自编码器(autoencoder)。此时网络大致可以划分为编码器(encoder)和解码器(decoder)两部分,其中编码器用来将输入\(x\)编码为\(h\)而解码器用来将编码\(h\)解码为\(\hat{x}\)。

自编码器的核心是学习到一个恒等映射使得\(x\)与\(\hat{x}\)尽可能接近。为了防止网络直接记忆了\(x\)我们需要对编码\(h\)进行一些限制,称为信息瓶颈(bottleneck)。

设置信息瓶颈有很多种方法,其中最简单的是约束\(h\)的维度使它小于输入\(x\)的维度,此时的自编码器称为欠完备自编码器。通过最小化重构误差,欠完备自编码器可以学习到数据中更为核心和重要的信息。

另一种常用的设置信息瓶颈的方式是将\(h\)的正则项加入到损失函数中,在训练时一起进行优化。
